
When it comes to making decisions we are often faced with the issue of dealing with uncertainties, meaning that we have to make decisions on the basis of the limited information we have, and our best understanding at a point in time.
In this post I want to tell a story that hopes to shine some light on the multiple places where uncertainty might be lurking, and the eventual costs from such uncertainties and how to deal with those costs.
Note: This is a data heavy post, easier to read by anyone with some exposure to statistics, but I tried to make the story as easy to read as possible.
THE GOOD & BAD BEES STORY
In this story we have:
- Sophie: the owner of business that relies on Bees (for example a honey farm)
- Tim: Sophie’s husband and COO of the company
- Reggie: A smart employee
The business is faced with a great threat, Bad Bees have started to appear that damage the business by effectively poisoning Good Bees… what to do?
Sophie: “Tim!, come over? so what is the issue with the Bad Bees?”
Tim: “Well we might have 10%-20% bad bees and they generally spoil the work of 3-5 bees and…
Sophie: “Cut with the numbers tale! What’s the damage?”
Tim: “Well, revenues down at least 30%…possibly 100%”
Sophie: “Wow, ok you got my attention now …”
Reggie: “Well, we have some news from the Govt, we should be able to manage some of the impact… the bad bees are larger and hotter than normal ones, but otherwise totally similar… we can try and identify them and shoot them with lasers!”
Tim: “We have lasers?”
Reggie: “Yes, just in case”
Tim: “Ok, how does that work?”
Reggie: “See below, it’s a chart showing the Bees sizes and body temperatures released by the Govt…”
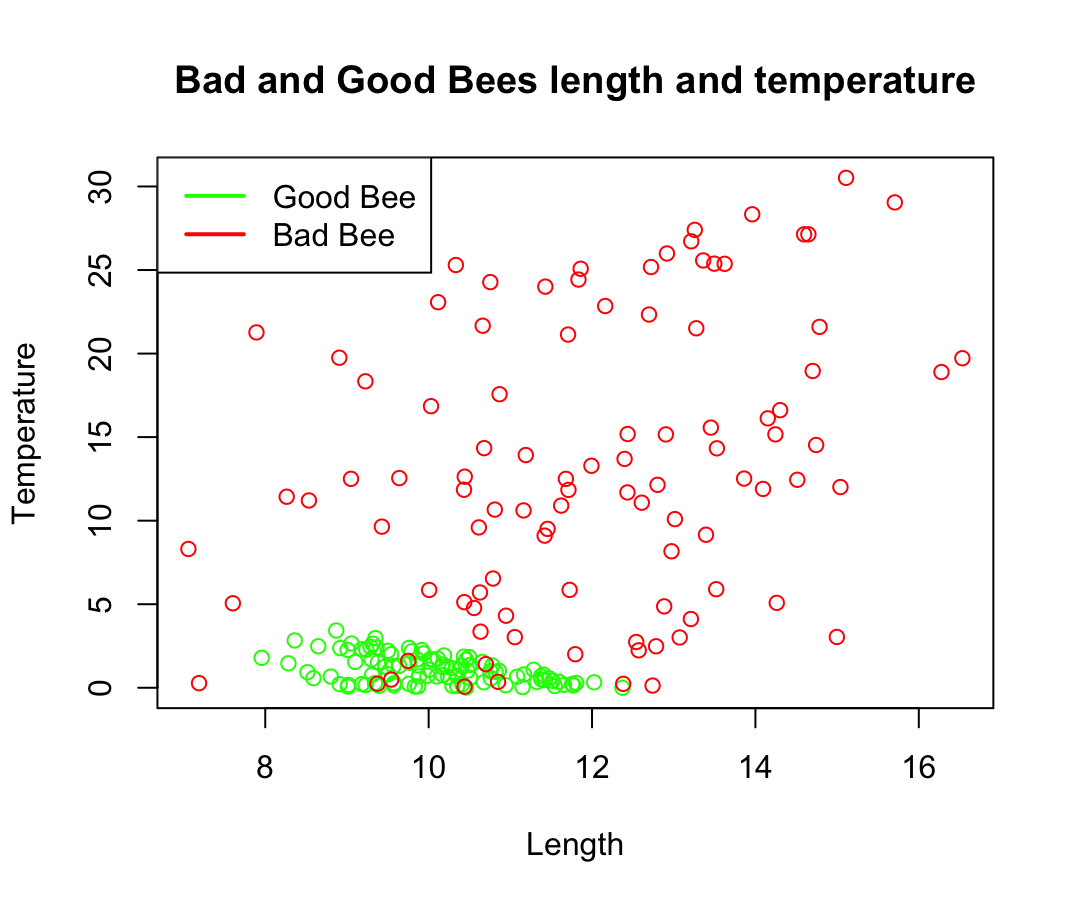
Tim: “What does that mean?”
Sophie: “Tim, aren’t you supposed to be clever? It means that we can try and classify Bees in Good or Bad Bees using length and temperature and eventually shoot the bad ones with the lasers! Isn’t it obvious?”
Reggie: “That’s right Sophie but… we can’t rely on the temperature unfortunately, current detectors are not able to measure that with any reliability, our cameras can calculate the Bee body length very accurately though and then… “
Sophie: “Lasers! I like the plan, work it out and bring me the numbers ASAP”
Reggie goes back to his team and they start to work through a solution.
We see the first uncertainty coming in, if we could use temperature and body length the issue could be solved, but we will need to rely on limited information. Knowing only the length, leave us with uncertainty (potentially solved with body temperature) on whether a Bee is Good or Bad.
See below:
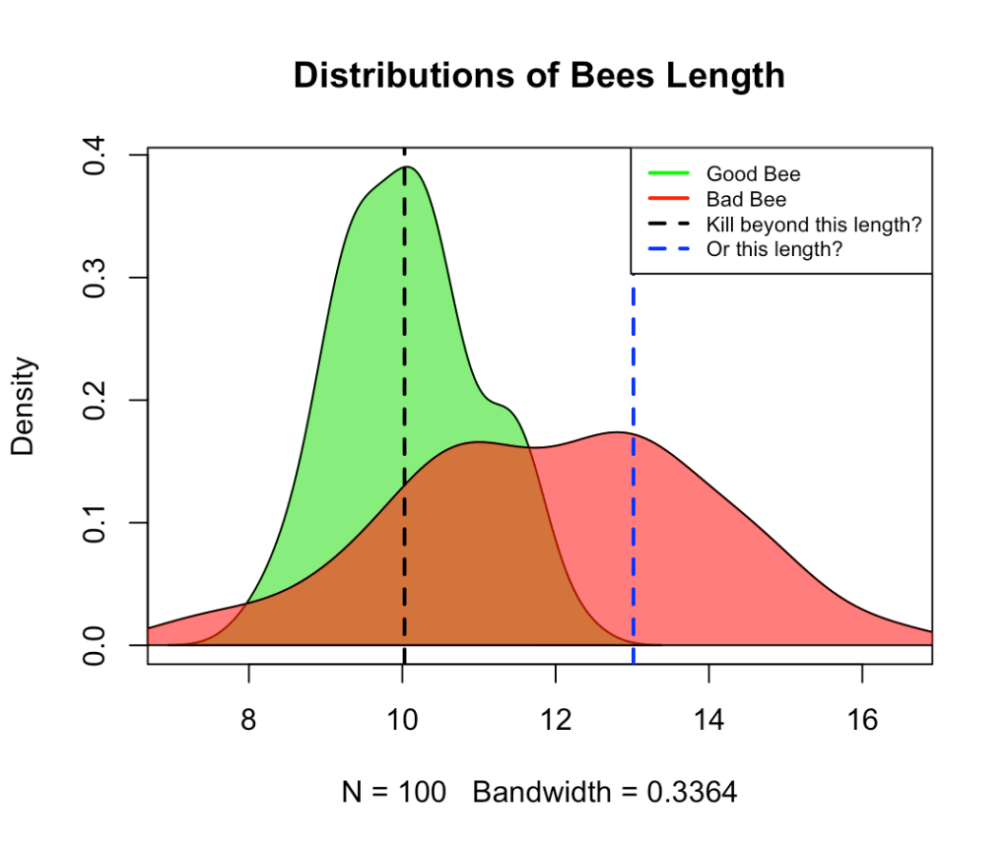
With a sample of a 100 genetically tested Bad and Good Bees it looks like the Good bees are about 10cm (…yes in this world we have engineered massive bees, not sure why) whilst Bad Bees are often much larger. We now have a second source of uncertainty, not only we can’t rely on temperature data, but we are also having to rely on limited data to assess the difference in lengths between Good and Bad Bees.
Reggie nevertheless goes ahead and fits a machine learning model that tries to predict whether a Bee is Good or Bad basis the body length and he gets the below ROC curve:
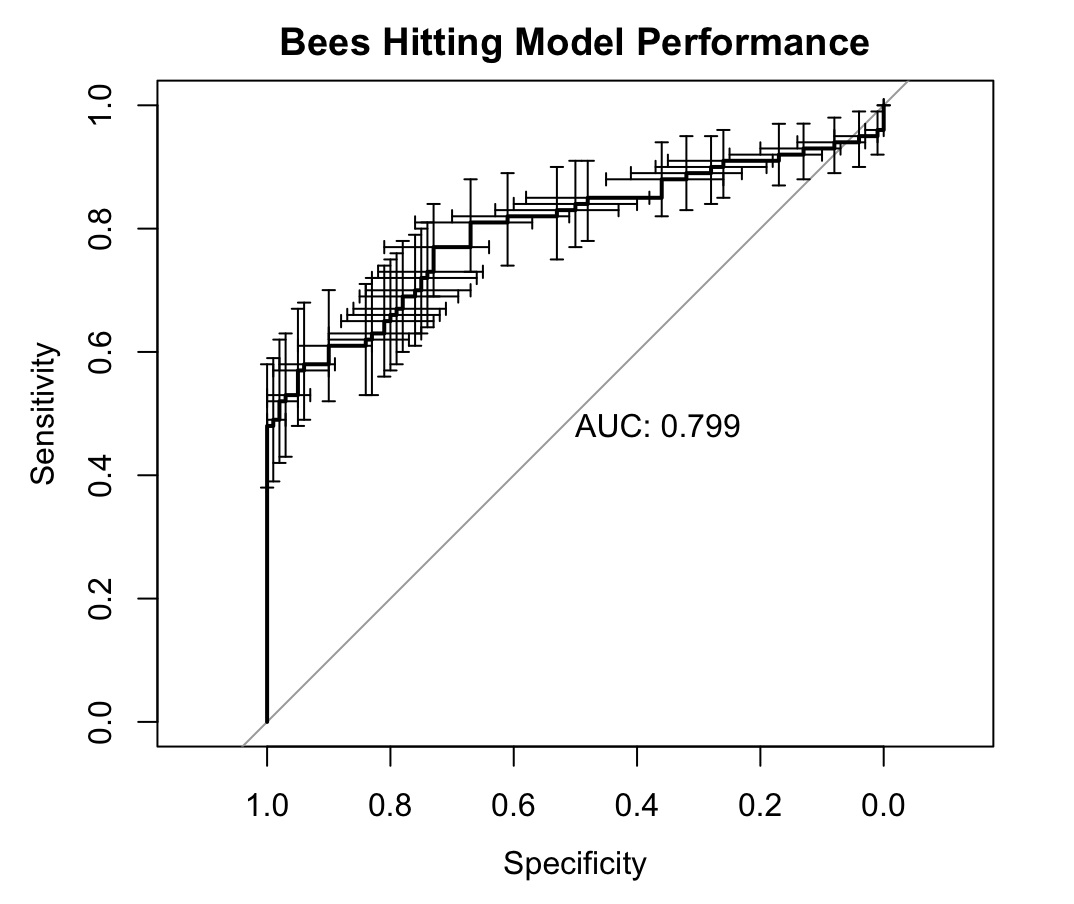
ROC stands for “Receiver Operating Characteristic”, but that curve basically tells us how good Reggie has been with his modelling, the higher the AUC (area under the curve) the better.
The AUC tells us what is the probability that I can tell the two Bees apart by leveraging a certain body length threshold (e.g. 10cm).
Overall the model is good, it will be right 80% of the times on average. The Lasers will work well… on average, but if you go back to the previous chart (Bees lengths chart) you can see that, despite the good AUC, we have a large overlap in length distributions among the Bees, in fact about 50% of Bad Bees have body length that is very common for Good Bees too, so always beware of averages. It is relatively easy to be right on average, but the lasers will struggle to be right consistently (will share more about this in a later post).
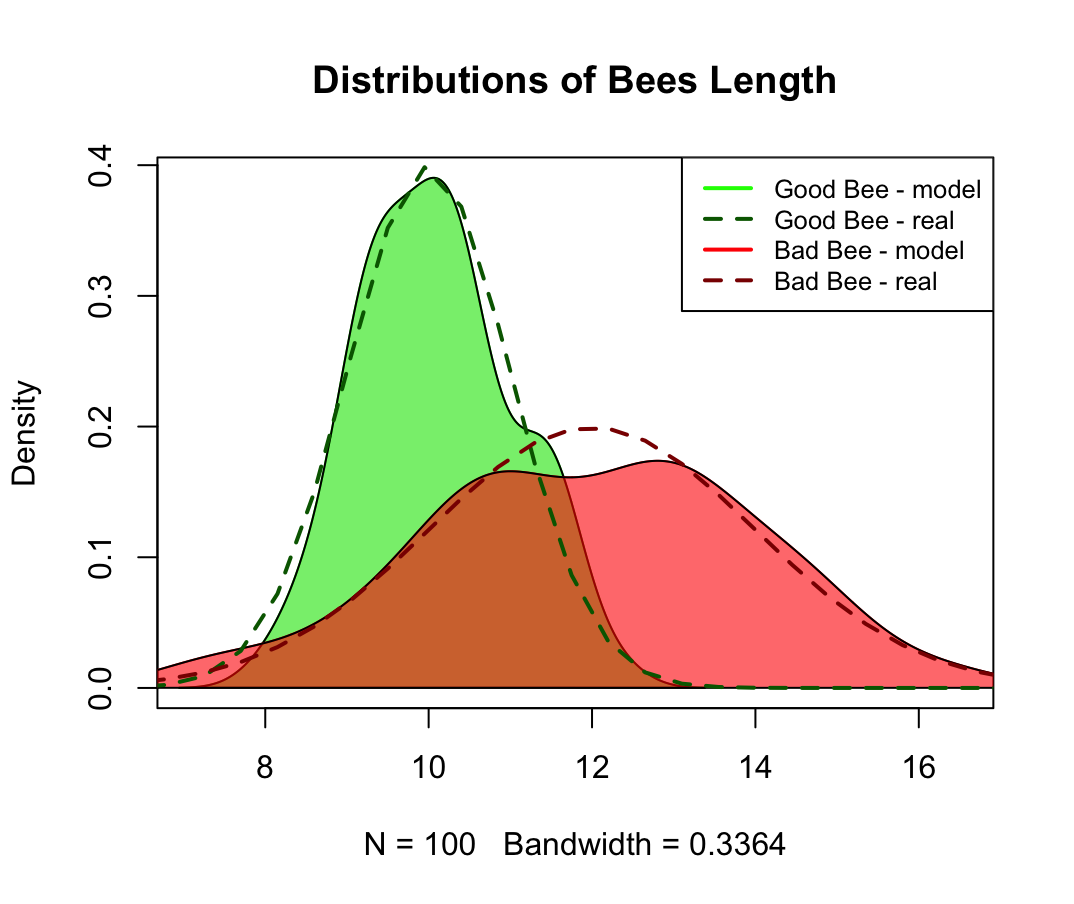
Well, here we actually have a third source of uncertainty: did Reggie do his modelling as well as possible? Is this predictive model as good as it gets given the previous two uncertainty constraints?
Given I have simulated the data I can tell you he got it almost right, the best possible model would be right 83% of the time instead of the ~80% Reggie achieved, but that 3% can be very costly indeed as it means being wrong once every 5.8 laser beams rather than once every 5 (yes, ROC curves are hard to read and interpret…)
Finally, if you remember we have additional uncertainties, which are of a nature beyond the modelling exercise, those are uncertainties that we have not yet been able to model, that is:
- Prevalence: Govt says about 10%-20% of Bees will be Bad bees, that’s quite a range
- Cost of the Bad bees: Govt says that a Bad Bee is likely to spoil the work of 3-5 Good bees, still quite a range…
Reggie goes back to Sophie and Tim.
Reggie: “Ok I have got the plan. We have developed a predictive model…”
Sophie: “With ChatGPT? I know that thing is smarter that Tim…”
Reggie: “No, no we have done it ourselves…”
Sophie: “Oh my good…”
Reggie: “No, don’t be like that, the news are good! but I need your help and opinion on how much Bad Bees we want to be prepared for, and what level of damage…”
Sophie: “Ask ChatGPT Reggie!”
Reggie: “The chat thing doesn’t know!….”
Tim: “Hey, can we move beyond the ChatGPT stuff?”
Sophie: “Reggie, explain…”
Reggie: “Ok I have developed this predictive model, it can be right 80% of the time, impressive I know…”
Sophie: “Is that impressive?, anyway continue…”
Reggie: “Right right, yes the model is good but we need to decide on a threshold of length for the lasers, the model leverages the length of the Bee that we detect from our cameras, and we need to decide when to fire. Take a look at the chart…”
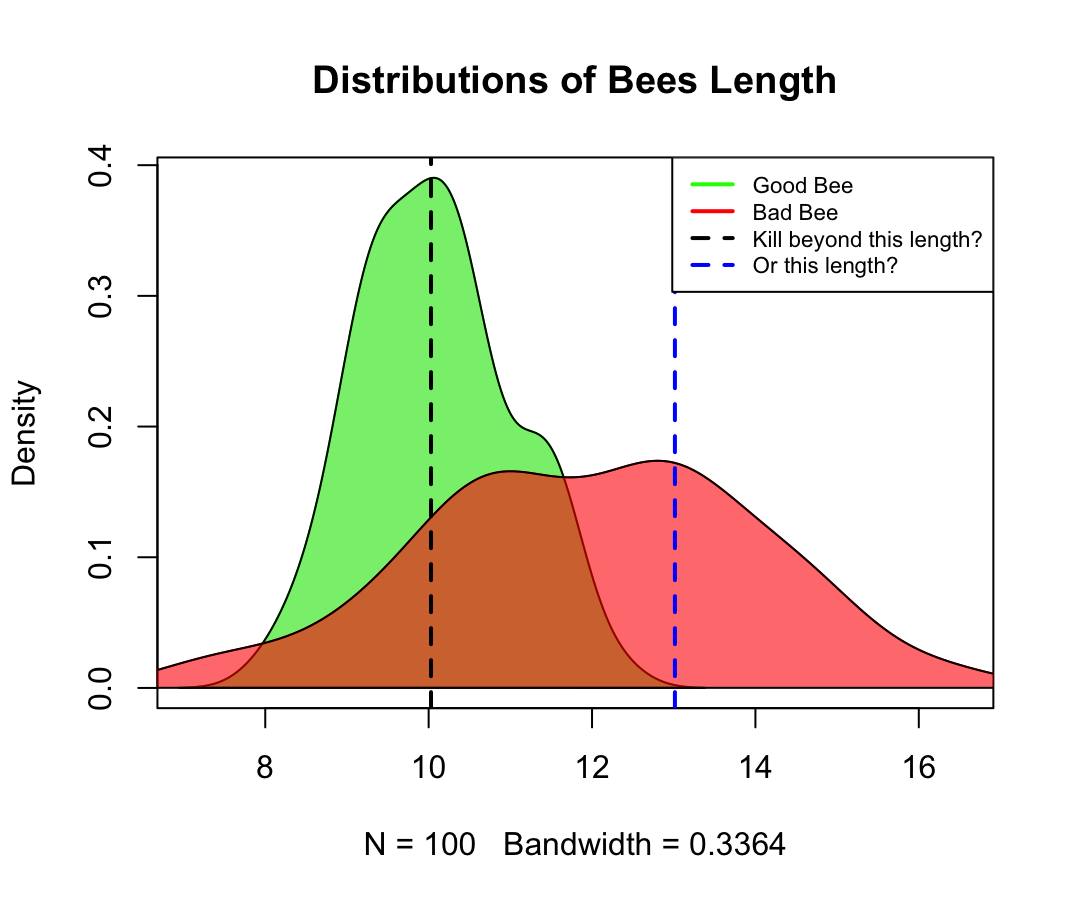
Reggie: “If we believe the Bad Bees will be 20%, and will damage the work of 5 good Bees we need to start firing any Bee longer than 10cm… this will mean killing half of Good Bees, but also 85% of the Bad ones!”
Sophie: “That’s not good enough! You want to kill 50% of our lovely Bees!!”
Tim: “Calm down Sophie, we will ask ChatGPT later, let him finish…”
Reggie: “Right, then if we assume that prevalence will be 10% and damage will be that of 3 Good Bees we can hit at ~13cm, this will kill almost no Good Bees! but it will also only hit about 30% of the Bad Bees…”
Sophie: “Ok, let’s talk money, what are we looking at in terms of impact on revenues? how much revenue we will loose if we hit 50% of our Good Bees but Bad Bees won’t be that many? or that Bad?”
Reggie: “That would be 55% lower revenues Sophie…”
Sophie: “… What about if we are going for the less aggressive scenario, but the Bad Bees are actually going to be super Bad?”
Reggie: ” We would lose 80% in that scenario Sophie”
Tim: “There you have it! the lasers should fire away!…”
Sophie: “Wait, I have just asked the Chat thing, the proposed approach is to start with the super firing strategy, but then reassess every week or so by sending the dead Bees for a genetic assessment to check prevalence”
Tim: “We can also measure the output of the Good Bees work to see what’s the damage from the Bad Bees we won’t hit?”
Sophie: “Finally you say something clever Tim! Ok we will proceed this way… get the lasers and videos ready, as well as the process to work together with Govt on a timely manner, and the predictive model governance to make sure things are smoothly updated”
Reggie, why is uncertainty so costly?”
Reggie: “I don’t know Sophie, it’s a matter of numbers I guess…”
The little story finishes here and I can tell you that Sophie and team will make it, and will eventually also sell their machine learning assets to smaller farms eventually growing their business beyond the small operation it was!
Given I have fully simulated the data it is interesting to note that the various uncertainties carry very different costs.
The sample and model uncertainty, in this case, accounts for about 10% of the costs of the uncertainty, whilst, in various scenarios the uncertainty on prevalence or “Badness” of the Bees is actually more prominent, accounting for the remaining 90% of costs.
So, here Sophie’s monitoring approach will be fundamental, whilst Reggie’s team improvements on the modelling might not change much the outcomes.
This was a very simple example with very well behaved data (I simulated the whole process with Normal distributions for the data scientists out there), but the nature of uncertainties and their costs can be much larger.
Let me leave you with two questions:
How often do you think of where the uncertainties lie? And which are more or less costly or addressable?
How often that thinking is clearly expressed quantitatively?
