
A while back I discussed in a post some of the nuances of data driven decision making when we need to answer a straight question at a point in time e.g. : “shall we do this now?”.
That was a case presented as if our decision “now” would have no relationsip to the future, meaning that it would have no impact on our future decisions on the same problem.
Luckily, often, we do know that our decisions have an impact on the future, but the issue here is slightly different, we are looking not only on impact in the future but an impact on future decisions.
This is the problem of sequential decisioning. Instead of “shall we do this now?” answers the questions:
“Shall we adopt this strategy/policy over time?”
In other words it tries to solve a dynamical problem, so that the sequence of decisions made could not have been different no matter what happened. When you have an optimal solution to this problem, whatever decision is made, at any point in time, is a decision that one would never regret.
I will answer three questions here:
- What is an example of such a problem?
- Is there a way to solve such problems?
- What is the relationship with DeepSeek and politics?
Sequential decisioning problem example – Customers Enagegement Management
A typical example could be that of working on marketing incentives on a customer base. The problem is that of deriving a policy for optimal marketing incentives depending on some measures of engagement in the customer base.
Why is it sequential? Because we have a feedback loop between what we plan to do, the marketing incentive, and the behaviour of our customers that triggers customer incentives: engagement.
Whenever we have such loops we cannot solve the problem at one point in time and regardless of the future.
The solution could look something like: “Invest $X in customer rewards whenever the following engagement KPIs, email open rate, web visits, product interaction etc.etc. drop below certain levels.
It is important to note that we need something to aim for, e.g. maximise return on marketing incentives.
Does a solution to such problems exist?
The good news is that yes, solutions exist, but we have been able to deal only with such cases that would be amenable to some mathematical/statistical modelling.
We can 100% find a solution If we have a good model that answers the following:
- How does a given marketing incentive influence customers enagement on average?
- Given a certain level of customer engagement, what is the expected value of the relationship with the customer?
- How does the engagement of our customer evolves overtime, in absence of any incentive?
So we do need some KPIs that give us a good sense of what level of cusotmer engagement we have, and we need to have a sense of what is the expected value of the relationship with the customer given a particular set of KPIs. To be clear what we need is something true on average, and at least over a certain period of time.
Example, we should be able to say that, on average, a customer using our products daily for the past month will deliver X value over 2 years.
We also need to be able to say that a given marketing incentive, on average, increase customers daily enagement by X% and costs some defined amount of $
We also need to be able to say something like: our customer engagement rate tends to decrease X% every few months, again on average.
The above modelling of engagement and customer value is not something that most businesses would find difficutl today. Engagement rates, or attrition rates overtime, are easy to get, as well as results of marketing campaigns on engagement rates. Harder to get is a reliable estimate of lifetime value given current engagement metrics, but we can solve for a shorter time horizon in such cases.
Richar Bellman is the mathematician credited for having solved such problems in the most general way.
His equation, the Bellman equation, is all you need after you have a mathematical model of your problem.
The equation, in the form I’d like to present it is the one below, where V is the value of the optimal policy 
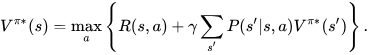
It says the following:
The optimal strategy, depending on parameters a (e.g. how $ spent on incentives), is that which maximizes the instant rewards now, as well as the expected future rewards (future rewards conditional on the policy), no matter what the variables of the probelm are at that point in time (e.g. customer engagement and marketing budget left).
It is a beautiful and intuitive mathematical statement which is familiar to most humans:
The best course of action is that which balances instant gratification with delayed gratification.
We all work this way, and this is arguably what makes us human.
To be clear this problem can be, and it is solved, in a large variety of sequential decisioning problems.
The Bellman equation is the basic tool for all planning optimizations in supply management, portfolio management, power grid management and more…
Politics?
Well, in some sense politics is the art of collective, at least representative, policy making. And here a problem obviously arises: How to dial well instant versus delayed gratification when the views of the collective might differ? What if the collective doesn’t even agree on the various aspects of the problem at hand? (e.g. the KPIs, the expected rewards etc.etc.).
A key aspect of this should be the following: LEARNING.
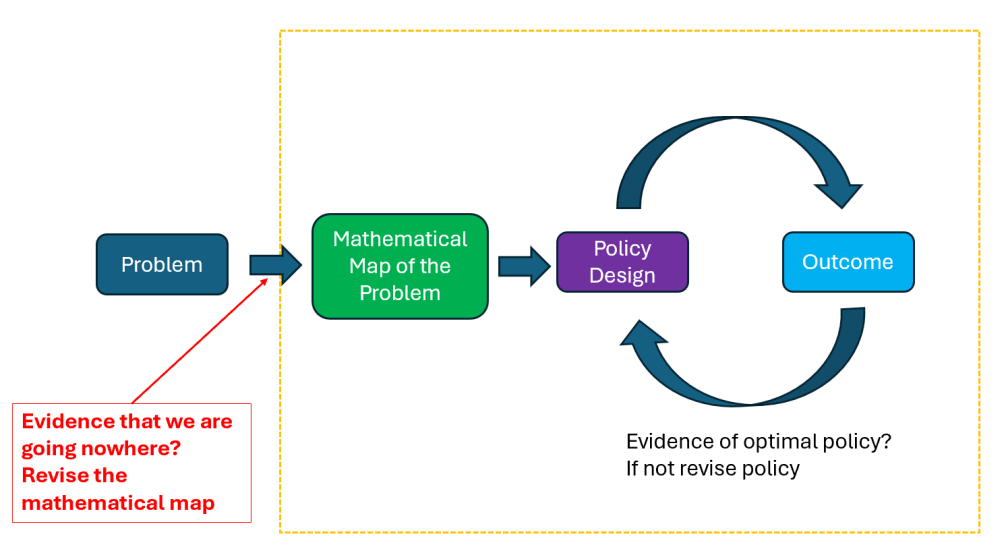
The illustration below should be of guidance:
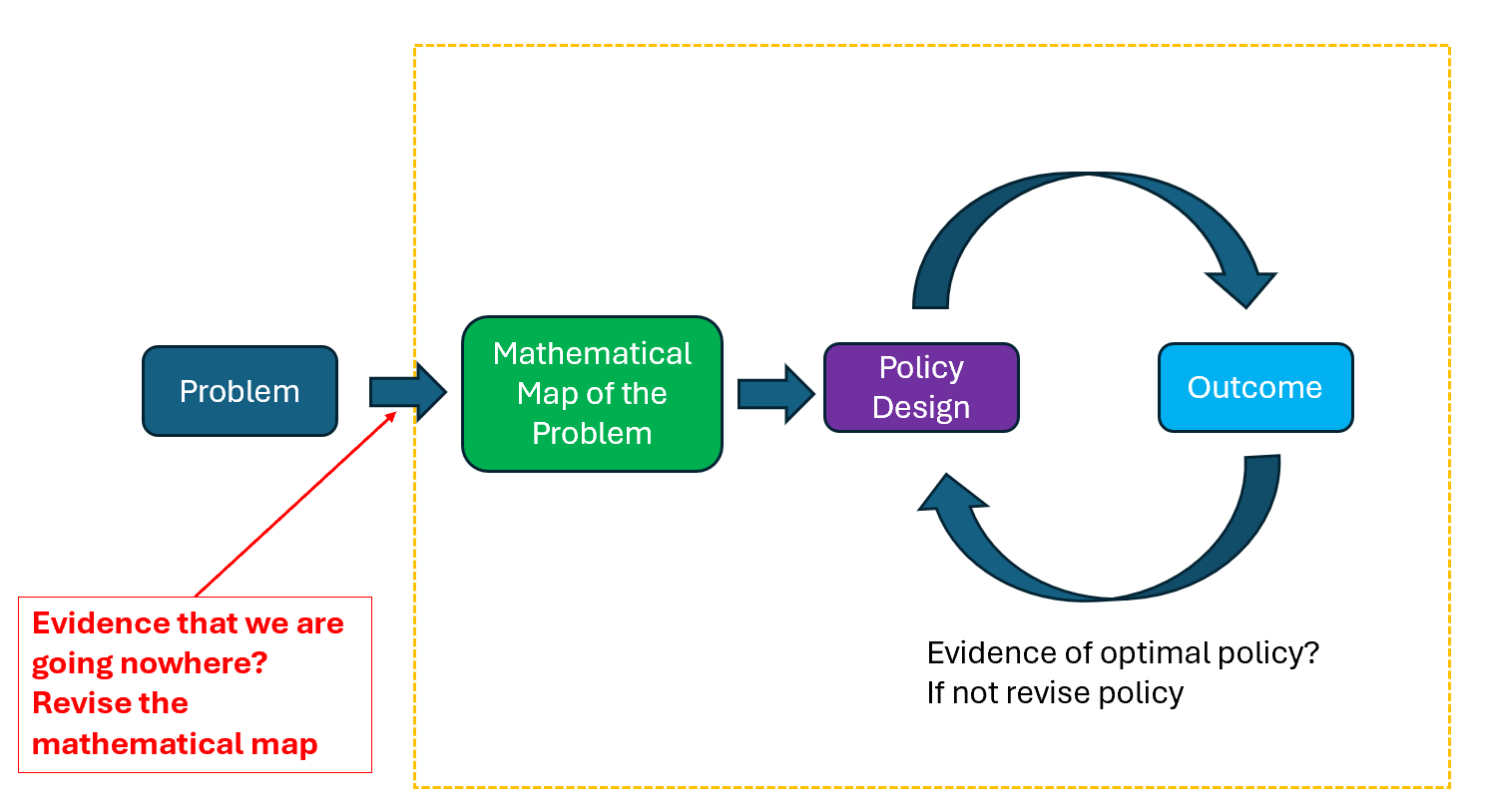
There has to be a feedback loop as the Bellman equation gives conditions for optimality, but often the solution can only be found iteratively. Futhermore, we also need to be open minded on revising the overall model of the problem, if we gather evidence that the conditions for optimality do not seem to come about.
So we have multiple challenges, which are true for politics but also for business management. We need:
- Consensus on how to frame the problem
- A shared vision on the balance between instant versus delayed rewards (or my reward versus your reward)
- A framework for adapting as we proceed
The above is what I would call as being “data driven”- basically “reality” driven, but it is hard to get there. We all obviously use data when we have it, but the real challenge is to operate in such a way that the data will be there when needed.
How about DeepSeek?
If you have followed thus far you might have understood that solving a sequential problem basically involves algorithms to learn the dynamics between a policy maker action (e.g. marketing $ spent) and the long term feedback of the policy. This is the principle behing “reinforcement learning” in the AI world, as one want the learning to be reinforced by incentives for moving in the right direction. This was considered as a very promising framework for AI in the early days, but it is indeed an approach that requires time, and a fair bit of imagination as well as data, and was not pursued in recent years… until DeepSeek stormed the AI world.
A key element of DeepSeek successful R1 generative AI model was that it leveraged reinforecement learning, which forced it to develop advanced reasoning at a lower cost.
This was achieved through very clever redesigning of the transformer architecture, but I won’t go through it (as I have not yet understood it well myself).
As usual let me point you to a great book on the above topics.
My favorite is “Economics Dynamics” by John Stachursky. Great resource on sequential problem solving under uncertainty. Pretty theoretical, but that’s inevitable here.

